Caching Best Practices in REST API Design
Caching API Responses
API caching can save servers some serious work, cut down on costs, and even help reduce the carbon impact of an API. However, it is often considered an optimization rather than what it truly is: an integral part of API design.
A fundamental part of REST is APIs declaring the “cacheability” of resources. When working with HTTP there are many amazing caching options available through HTTP Caching; a series of standards that power how the entire internet functions. This can be used to design more useful APIs, as well as being faster, cheaper, and more sustainable.
What is HTTP caching?
HTTP caching tells API clients (like browsers, mobile apps, or other backend systems) if they need to ask for the same data over and over again, or if they can use data they already have. This is done with HTTP headers on responses that tell the client how long they can “hold onto” that response, or how to check if it’s still valid.
This works very differently from server-side caching tools like Redis or Memcached, which cache data on the server.
HTTP caching happens on client-side or on intermediary proxies like Content Delivery Networks (CDNs), acting as a proxy between the client and the server and storing responses for reuse whenever possible.
Think of server-side caching as a way to skip application work like database calls or outgoing HTTP requests, by fetching precomputed results from Redis or Memcached. HTTP caching reduces traffic and computational load further, by reducing the number of requests that even reach the server, and by reducing the number of responses that need to be generated.
How does it work?
HTTP caching is driven by cache headers. In its most simple form, when an API sends a response, it includes instructions that tell the client and other network components like CDNs if they are allowed to cache the response, and if so for how long.
The guide on API responses briefly introduced the Cache-Control header:
HTTP/2 200 OKContent-Type: application/jsonCache-Control: public, max-age=18000
{ "message": "I am cached for five minutes!"}Here the server is telling the client (and any cache proxies) that they can cache this response for 5 minutes, and they can share it with other clients too. This means that a client can use this data for up to 5 minutes without checking back with the server, and when that time has expired it will make a new request.
Fetching data, processing it, and sending it back to the client takes time and resources. Even when all of those processes are as optimized as possible, if the data hasn’t changed, why bother repeating these requests? Instead of wasting resources answering the same requests over and over again, the server could be processing more useful requests, saving energy, and save money by scaling down unnecessary server capacity.
Cache-Control
Defined in RFC 9111: HTTP Caching, this header sets out the rules. It tells clients what to do with the response:
Cache-Control: max-age=3600— The client can use this data for up to an hour (3600 seconds) without checking with the server.Cache-Control: no-cache— The client must check with the server before using the cached copy.Cache-Control: publicorprivate— Defines whether just the client or everyone (like proxies) can cache it.
These directives can be combined in various combinations for more control, with handy advanced options like s-maxage for setting how long data should live on shared caches like CDNs.
Some simple APIs will only use Cache-Control to manage caching, but there’s another powerful tool in the cache toolbox: ETag.
ETag
ETags (short for “Entity Tags”) are like a fingerprint for a particular version or instance of a resource. When the resource changes, the ETag will change. No two versions of a resource should have the same ETag, and the ETag is unique to the URL of the resource.
When a server sends a response, it can include an ETag header to identify that version of the resource:
HTTP/2 200 OKContent-Type: application/jsonETag: "abc123"
{ "message": "Hello, world!"}Then when a request is reattempted for whatever reason, the client sends a request with the ETag in the If-None-Match header. Doing this basically says “Only download the response if the ETag is different to this”.
GET /api/resource HTTP/2If-None-Match: "abc123"- If the server responds with
304 Not Modified, it tells the client, “That response is still good. Nothing has changed since then, so no need to download it again.” - If the data has changed, the server returns the new data with a new ETag.
This is especially helpful for large responses that don’t change often, especially when combined with Cache-Control. Sending Cache-Control and ETag lets the client confidently reuse the data for a while without even needing to send a HTTP request to the server, then after that time it can switch to doing a check for changes instead of downloading the whole response again.
All of this is done without the client needing to know anything about the data, or how it’s stored, or how it’s generated. The server will handle it all, and the client will just keep requesting the data, allowing the cache-aware HTTP client to do the heavy lifting.
Using Cache-Control and ETags in code
Let’s add these headers to a basic Express.js API to see how it might look on the server-side.
const express = require("express");const app = express();
app.get("/api/resource", (req, res) => { const data = { message: "Hello, world!" }; // Simulated data const eTag = `"${Buffer.from(JSON.stringify(data)).toString("base64")}"`;
if (req.headers["if-none-match"] === eTag) { // Client has the latest version res.status(304).end(); } else { // Serve the resource with cache headers res.set({ "Cache-Control": "max-age=3600", // Cache for 1 hour ETag: eTag, }); res.json(data); }});
app.listen(3000, () => console.log("API running on http://localhost:3000"));The ETag is generated by hashing the data, then the server checks if the client has the latest version. If it does, it sends a 304 Not Modified response, otherwise it sends the data with the ETag and Cache-Control headers.
In a real codebase, would be doing something like fetching from a datasource, or computing something that takes a while, so waiting for all of that to happen just to make an ETag is not ideal. Yes, it avoids turning that data in JSON and sending it over the wire, but if the API is going to ignore it and send an 304 Not Modified header with no response, the data was loaded and hashed for no reason.
Instead, an ETag can be made from metadata, like the last updated timestamp of a database record.
const crypto = require('crypto');
function sha1(data) { const crypto.createHash('sha1').update(data).digest('hex');}
const trip = Trips.get(1234);
const eTag = `"${sha1(trip.updated_at)}"`;This example creates a SHA1 hash of the updated time, which will automatically change each time the record is updated. No need to specify the name of the Trip resource, or even mention the trip ID, because an ETag is unique to the URL and that is already a unique identifier.
When working with resources that have their own concept of versioning, why not use that version number as an ETag instead of creating one from something else.
const trip = Trips.get(1234);
const eTag = `"${trip.version}"`;HTTP/2 200 OKContent-Type: application/jsonETag: "v45.129"Regardless, ETags are brilliant and easy to reconcile. If clients don’t use them, it doesn’t have any effect, but if they do use a HTTP client with cache middleware enabled then both the client and the server can save a lot of time and resources.
Public, private, and shared caches
Using Cache-Control headers its possible to specify whether the response can be cached by everyone, just the client, or just shared caches. This is important for security and privacy reasons, as well as cache efficiency.
public— The response can be cached by everyone, including CDNs.private— The response can only be cached by the client.no-store— The response can’t be cached at all.
Note
When a response contains an Authorization header, it’s automatically marked
as private to prevent sensitive data from being cached by shared caches.
This is another reason to use standard auth headers instead of using custom
headers like X-API-Key.
Which resources should be cached?
Some people think none of the data in their API data is cacheable because “things might change.” It’s rare that all data is so prone to change that HTTP caching cannot help. All data is inherently out of date before the server has even finished sending it, but the question is how out of date is acceptable?
For example, a user profile is not likely to change particularly often, and how up to date does it really need to be? Just because one user changes their biography once in a year doesn’t mean that all user profiles need to be fetched fresh on every single request. It could be cached for several hours, or even every day.
When talking about more real-time systems, one common example is a stock trading platform. In reality, most trading platforms publish a new public price every 15 minutes. A request to /quotes/ICLN might return a header like Cache-Control: max-age=900, indicating the data is valid for 900 seconds. Even when clients are “polling” every 30 seconds, the network cache will still be able to serve the response for 15 minutes, and the server will only need to respond to 1 in 30 requests.
Some resources might genuinely change every second, and depending on the traffic patterns network caching could still be helpful. If 1,000 users are accessing it simultaneously then network caching will help significantly reduce the load. Instead of responding to 1,000 individual requests per second, the system can reuse a single response per second. This would be a 99.9% reduction in server load, and a 99.9% reduction in bandwidth usage.
A safe default for most data is to apply some level of max-age caching (such as 5 minutes, an hour, a day, or a week, before it needs to be refreshed) paired with an ETag to check for fresh data past that time if the response is large or slow to generate. The introduction of ETags to an API can increase confidence in using longer cache expiry times.
Designing cacheable resources
All new APIs should be designed with cachability in mind, which means thinking about how to structure resources to make them more cacheable. The changes needed to make an API more cacheable are often the same changes that make an API more efficient and easier to work with.
Resource composition
One of the largest problems API designers face is how to sensibly group data into resources. There’s a temptation to make fewer resources so that there are fewer endpoints, with less to document. However, this means larger resources, which become incredibly inefficient to work with (especially when some of the data is more prone to change than the rest).
GET /invoices/645E79D9E14{ "id": "645E79D9E14", "invoiceNumber": "INV-2024-001", "customer": "Acme Corporation", "amountDue": 500.0, "amountPaid": 250.0, "dateDue": "2024-08-15", "dateIssued": "2024-08-01", "datePaid": "2024-08-10", "items": [ { "description": "Consulting Services", "quantity": 10, "unitPrice": 50.0, "total": 500.0 } ], "customer": { "name": "Acme Corporation", "address": "123 Main St", "city": "Springfield", "state": "IL", "zip": "62701", "email": "acme@example.org", "phone": "555-123-4567" }, "payments": [ { "date": "2024-08-10", "amount": 250.0, "method": "Credit Card", "reference": "CC-1234" } ]}This is a very common pattern, but it’s not very cacheable. If the invoice is updated, the whole invoice is updated, and the whole invoice needs to be refreshed. If the customer is updated, the whole invoice is updated, and the whole invoice needs to be refreshed. If the payments are updated, the whole invoice is updated, and the whole invoice needs to be refreshed.
We can increase the cachability of most of this information by breaking it down into smaller resources:
GET /invoices/645E79D9E14{ "id": "645E79D9E14", "invoiceNumber": "INV-2024-001", "customer": "Acme Corporation", "amountDue": 500.0, "dateDue": "2024-08-15", "dateIssued": "2024-08-01", "items": [ { "description": "Consulting Services", "quantity": 10, "unitPrice": 50.0, "total": 500.0 } ], "links": { "self": "/invoices/645E79D9E14", "customer": "/customers/acme-corporation", "payments": "/invoices/645E79D9E14/payments" }}Instead of mixing in payment information with the invoice, this example moves the fields related to payment into the payments sub-collection. This is not only makes the invoice infinitely more cacheable, but it also makes space for features that are often used in an invoice system like payment attempts (track failed payments) or partial payments. All of that can be done in the Payments sub-collection, and each of those collections can be cached separately.
The customer data is also moved out of the invoice resource, because the /customers/acme-corporation resource already exists and reusing it avoids code duplication and maintenance burden. Considering the user flow of the application, the resource is likely already in the browser/client cache, which reduces load times for the invoice.
This API structure works regardless of what the data structure looks like. Perhaps all of the payment data are in an invoices SQL table, but still have /invoices and /invoices/{id}/payments endpoints. Over time as common extra functionality like partial payments is requested, these endpoints can remain the same, but the underlying database structure can be migrated to move payment-specific fields over to a payments database table.
Many would argue this is a better separation of concerns, it’s easier to control permissions for who is allowed to see invoices and/or payments, and the API has drastically improved cachability by splitting out frequently changing information from rarely changing information.
Avoid mixing public and private data
Breaking things down into smaller, more manageable resources can separate frequently changing information from more stable data, but there are other design issues that can effect cachability: mixing public and private data.
Take the example of a train travel booking API. There could be a Booking resource, specific to a single user with private data nobody else should see.
GET /bookings/1234{ "id": 1234, "departure": "2025-08-15T08:00:00", "arrival": "2025-08-15T12:00:00", "provider": "ACME Express", "seat": "A12"}In order for a user to pick their seat on the train, there could be a sub-resource for seating:
GET /bookings/:my_booking_ref/seating{ "my_seat": "A12", "available_seats": [ "A1", "A2", "A3", "A4", "A5", "A6", ... ]}Creating the seating sub-resource like this will make a unique seating chart for every single user, because “all the seats” and “this users seat” have been mixed together. These responses could still be cached, but it would have to be a private cache because the generic information has been “tainted” with data unique to each user. 10,000 users would have 10,000 cache entries, and the chance/impact of them being reused would be rather small, so there isn’t much benefit to filling the entire cache with all this.
Consider breaking this down into two resources:
GET /bookings/:my_booking_ref- See booking details, including current seat.GET /trips/:trip_id/seats- List seat availability on the train.PUT /bookings/:my_booking_ref- Update booking (eg to reserve a seat).
By moving the seat information to the booking resource, the seating availability becomes generic. With nothing personalized about it at all, the resource can be cached for everyone who is trying to book a seat on this train.
There is no downside to caching this data, because it is the same for everyone. Even if it changes, it’s easy to grab the latest data from the server and suggest the user select another seat if it’s no longer available. This allows the seat availability to be cached for a long time, and only worry about refreshing the plan if the PUT request fails because a seat is no longer available.
Content Delivery Networks (CDNs)
HTTP caching works well when clients use it, and many do automatically, like web browsers or systems with caching middleware. But it becomes even more powerful when combined with tools like Fastly or Varnish.
These tools sit between the server and the client, acting like intelligent gatekeepers:
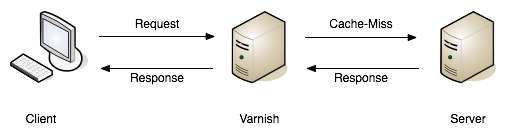
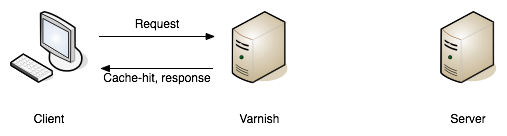
Client-caching like this is certainly useful, but the real power of caching comes when API web traffic is routed through a caching proxy. Using hosted solutions like Fastly or AWS CloudFront, this could be a case of changing DNS settings. For self-hosted options like Varnish, instead of pointing DNS settings to a hosted solution somebody will need to spin up a server to act as the cache proxy.
Many API gateway tools like Tyk and Zuplo have caching built in, so this functionality may already be available in the ecosystem and just need enabling.
Save emissions (and money) with HTTP caching
The Internet (and its infrastructure) is responsible for 4% of global CO2 emissions, and with 83% of web traffic coming from APIs, it becomes critical to consider the carbon impact of new APIs.
Each unnecessary API request costs server resources, bandwidth, and energy. That energy comes with a carbon footprint, whether it’s from a data center powered by renewable energy or not.
Summary
By reducing redundant requests, HTTP caching can:
- Cut down on server load (lowering hosting costs).
- Reduce network traffic (lowering bandwidth fees).
- Minimize energy consumption (a win for the environment).
Imagine millions of users no longer making unnecessary requests for unchanged data. Designing APIs to be cache-friendly from the start not only benefits the environment but also leads to faster, more efficient, and user-friendly APIs. It’s a win-win: better performance for users, lower operational costs for providers, and a positive impact on the planet.
Next time a new API is being designed, ask the question: How much of this data do I really need to serve fresh each time, and how much of this can be cached with a combination of Cache-Control and ETag headers?