Picking an API architecture
Planning to build an API? Choosing the right API architecture can feel like a gamble. You know that REST is reliable, GraphQL is gaining traction, gRPC is designed for high performance, WebSockets and SSE shine in real time, and SOAP… well, it’s a legacy standard, but it’s still out there. It’s a crowded ecosystem and the stakes are high: Choosing the wrong API architecture can lead to high technical debt, slower development, scalability issues, and, even worse, failure to meet long-term business goals.
This article cuts through the noise by focusing on a few key evaluation criteria – scalability, team expertise, integration needs, and maintainability – so that you can make a choice that meets immediate requirements while future-proofing your system.
Matching API architectures to project requirements
The starting point for choosing an API architecture isn’t the tools; it’s understanding your project’s requirements.
You’re building a system to expose and manage data, so you need to know from the outset what your users need, how your data flows, and what kind of interactions will occur.
Answering the following questions will help you define your project’s requirements and use case, guiding you to the right architecture for your needs.
- Are you building a simple client-server communication system?
- Does the project require real-time updates, or can it work with periodic data retrieval?
- Is your data model simple and predictable, or does it involve complex, nested structures?
- Are you dealing with sensitive information that demands strict security measures?
- Is this a lightweight project, or are you building a large-scale, scalable system?
Now that you’ve considered your project’s requirements, let’s take a closer look at the available architecture options.
REST: A proven architecture for client-server communication
Say you’re building an e-commerce platform. The application is straightforward at the start: Users can browse products, add items to their carts, and place orders. However, as the business plans to scale rapidly, the API must efficiently handle increased traffic and streamline developer onboarding.
This is where REST (REpresentational State Transfer) excels. REST uses a stateless, resource-based design, where endpoints represent entities like products or orders. Each endpoint corresponds to resources that can be manipulated using standard HTTP methods (GET, POST, PUT, and DELETE), making REST an intuitive choice for developers.
In the case of your e-commerce application, endpoints could be designed like this:
- GET
/productsto fetch a list of products. - POST
/ordersto place a new order.
Additionally, you can add endpoints to handle user authentication with OAuth or JWT.
Beyond authentication, REST’s resource-oriented design provides an intuitive and scalable foundation for extending your API. Whether you’re integrating real-time analytics, enhancing inventory tracking, or enabling multi-channel third-party interactions, REST offers a modular and predictable approach that fosters interoperability and future growth.
For example, you can use the Flask framework in Python to build a RESTful API. Here is how you can define a simple endpoint to fetch a list of products:
from flask import Flask, jsonify, request
app = Flask(__name__)
@app.route('/products', methods=['GET'])
def get_products():
products = [
{'id': 1, 'name': 'Product 1'},
{'id': 2, 'name': 'Product 2'},
{'id': 3, 'name': 'Product 3'},
]
return jsonify(products)
if __name__ == '__main__':
app.run(debug=True)The code above will expose a GET endpoint at the /products path, returning a JSON response with a list of products. This simplicity is one of REST’s key strengths – developers can quickly prototype and deploy APIs with minimal setup, using familiar web technologies and tools.
Other frameworks, such as FastAPI and Django, have many tools and built-in features following REST principles that can help you implement authentication, authorization, and more.
Scaling with REST: Better horizontally
Depending on the type of framework you are using, scaling horizontally (adding more servers) is straightforward because REST is stateless, meaning that each request from a client contains all the information necessary for the server to process it. Because the server doesn’t need to retain the session state between requests, distributing requests across multiple servers is straightforward, allowing new servers to be added without affecting the existing ones. This facilitates load balancing, as REST’s stateless nature allows load balancers to distribute the load evenly across multiple servers.
In the e-commerce application example, with 1,000 users accessing 500 products, the high-level view of the backend architecture would be as follows:
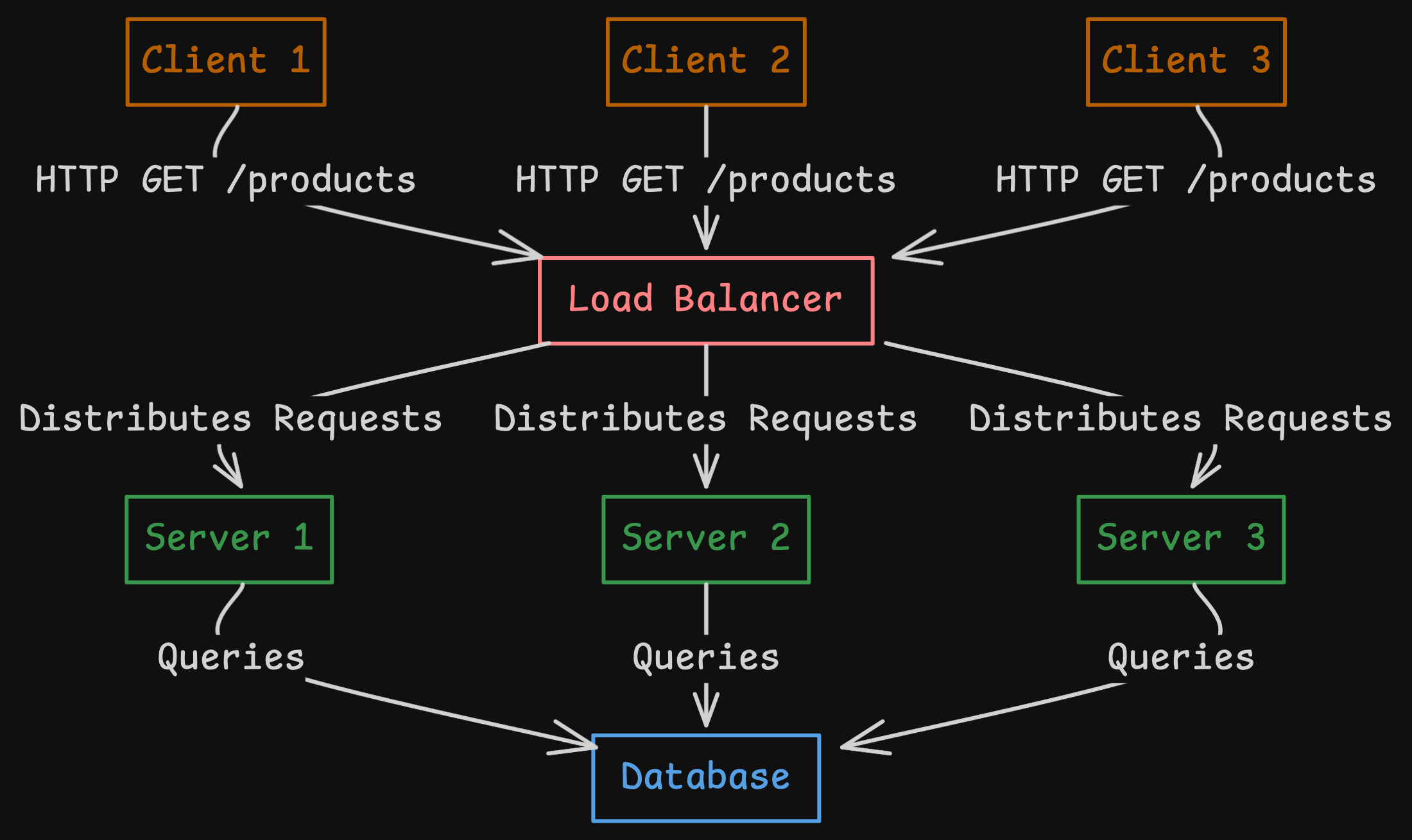
Here’s how the backend processes requests:
- A client makes a request.
- The request first goes to the load balancer, which then distributes the request to one of the servers.
- The server receives the request and processes it.
- The server sends a response back to the client.
This architecture can be easily replicated and expanded to support large-scale operations, enabling it to handle thousands or even millions of users simultaneously – something Instagram has successfully achieved.
GraphQL: An architecture to query exactly what you need
WebSocket and SSE are great for real-time communication, but what happens if you need an API that can handle some REST-like operations while allowing you to build a real-time system without too much hassle? Let’s discuss GraphQL.
Facebook launched in 2004 and quickly scaled to a multibillion-dollar company with over a billion users by 2012. During this growth, the Facebook team encountered significant challenges with their REST-based APIs. Some of the shortcomings they discovered with REST were:
- Slow on network: The iOS app had to make multiple API calls to fetch all the required data, causing delays.
- Fragile integration: Any API changes risked breaking the app, as updates weren’t always reflected in the client, leading to crashes.
- Tedious process: Developers had to manually update client-side code and models whenever the API responses changed, making maintenance time-consuming.
To overcome the limitations of REST, the Facebook team built a new API architecture called GraphQL .
GraphQL is a query language for APIs that allows clients to request exactly the data they need and the server to respond with only that data. For example, let’s say you are fetching data from an e-commerce API to retrieve a list of products. Here’s what the request would look like in a REST API:
GET /products
// response
[
{
"id": 1,
"name": "Product 1",
"price": 10.99,
"description": "This is a product description",
"createdAt": "2023-01-01T00:00:00.000Z",
"updatedAt": "2023-01-01T00:00:00.000Z"
}
]In a GraphQL API, the request would look like this:
query {
products {
id
name
price
}
}And the response would look like this:
{
"data": {
"products": [
{
"id": 1,
"name": "Product 1",
"price": 10.99
}
]
}
}The benefits of GraphQL include:
- Optimized network usage: GraphQL fetches only the required data in a single request, supports real-time updates via WebSockets, and uses a single endpoint for all queries and mutations, simplifying API management.
- Robust static typing: Reduces runtime errors, empowers clients to control response formats, and supports gradual backward compatibility without versioning, making server-side maintenance easier.
- Enhanced developer productivity: GraphQL offers tools like code generators and API explorers, automatically generates up-to-date documentation, and can easily integrate with existing REST APIs or backend systems.
Scaling with GraphQL
GraphQL is an excellent choice for scaling horizontally, as it allows you to build a single endpoint for all requests. It’s also easy to migrate to a GraphQL API, as it’s a query language, so you can use it with any programming language or framework. Uber ditched its old WebSocket-based live-chat architecture for GraphQL to take advantage of this scalability and flexibility.
While WebSocket APIs are great for real-time communication, the performance cost is high at scale. As the WebSocket protocol is better suited to vertical scaling, it isn’t ideal for building a region-wide API. Additionally, the Uber team had challenges with debugging, testing, and reliability in the old system, and found implementing a retry mechanism to be overly complex.
GraphQL addressed these issues and was easy to adopt, as it was already integrated into other Uber services.
Uber observed significant improvements after implementing the new architecture, including:
- Each machine supported 10,000 socket connections, with horizontal scaling enabling 20 times more events than the previous architecture.
- Existing traffic was routed through the new system with the old agent interface to test reliability, maintaining latency within defined SLAs.
- Offline agents were automatically logged out based on missed acknowledgments, resolving issues from the previous system where inactive agents increased customer wait times.
- The chat channel now handles 36% of Uber’s contact volume, with plans to increase its share in the coming months.
- The contract delivery error rate dropped significantly, from 46% to 0.45%.
- The new architecture reduced complexity with fewer services and protocols, and better observability.
With GraphQL, you can design an API architecture that evolves from a simple API to a real-time API, while scaling both horizontally and vertically. However, a common complaint about GraphQL is its lack of integration with OpenAPI, which makes sense as it’s a non-REST API.
gRPC: A new standard for high-performance APIs
gRPC (Google Remote Procedure Call) is a recent development in API design that promises a better API architecture by combining the scalability and simplicity of REST with the real-time capabilities of WebSockets while addressing some of the complexity and over-fetching challenges often associated with GraphQL.
In 2015, Google open-sourced gRPC, a modern, high-performance, open-source framework designed for efficient communication between microservices. While REST and GraphQL are widely used for APIs, gRPC was developed to address the limitations of traditional API architectures, especially in distributed systems and high-performance use cases.
gRPC is built on Protocol Buffers (Protobuf), a lightweight and highly efficient binary serialization format, which replaces the verbose JSON and XML payloads of REST and SOAP. It uses HTTP/2, which supports multiplexing, bidirectional streaming, and header compression.
In a REST API, retrieving a product would look like this:
GET /products/1
{
"id": 1,
"name": "Product 1",
"price": 10.99,
"description": "This is a product description",
"createdAt": "2023-01-01T00:00:00.000Z",
"updatedAt": "2023-01-01T00:00:00.000Z"
}In a gRPC API, the request would look like this:
syntax = "proto3";
service ProductService {
rpc GetProduct (ProductRequest) returns (ProductResponse);
}
message ProductRequest {
int32 id = 1;
}
message ProductResponse {
int32 id = 1;
string name = 2;
float price = 3;
string description = 4;
}To fetch a product:
- The client makes a GetProduct RPC call to the server, sending a binary-encoded request.
- The server responds with the requested data in a compact binary format.
This approach ensures smaller payloads, faster communication, and lower resource usage than REST or GraphQL. So, what makes gRPC a better choice for API architectures?
- High performance: Protobuf serialization and HTTP/2 make gRPC highly efficient regarding network bandwidth and processing speed, especially in low-latency environments.
- Bidirectional streaming: Unlike REST, gRPC natively supports real-time bidirectional communication using streams, which is ideal for video calls, live dashboards, or IoT applications.
- Strong typing: Protobuf provides a strongly typed schema, ensuring consistency between client and server implementations.
- Interoperability: gRPC supports multiple programming languages, making it an excellent choice for polyglot systems.
Scaling with gRPC
Despite being relatively new, gRPC has been widely adopted by leading tech companies like Google, Uber, and Netflix. In 2019, Uber moved its RAMEN tool to gRPC , a next-generation protocol. This upgrade improved the RAMEN tool’s speed and performance, delivering the following benefits:
- Instant acknowledgments that improve reliability, enable real-time RTT measurement, and help distinguish between message and network losses, with a slight increase in data transfer.
- Abstraction layers that support stream multiplexing, network prioritization, and flow control, optimizing data usage and reducing latency.
- Diverse payload serializations and robust client implementations across languages that enable easy support for various apps and devices.
WebSockets: An architecture for real-time communication systems
REST APIs are great for applications involving CRUD operations and structured request-response interactions where there is no need for real-time updates, and they scale reasonably well. But what happens when you need to handle real-time updates?
One solution is polling, a technique that allows the client to request the server periodically to check for updates. However, even if polling does the job, it can be inefficient and lead to many unnecessary requests, especially if the server is under heavy load, and it can flood the database.
Consider a real-time, high-frequency trading application – just one example where API design must strike a balance between speed and reliability. Users of this trading application need to see price changes as soon as they occur, but they also need to be able to send buying and selling orders to the server. While REST might seem like a viable option for building this app, you would likely face the following challenges:
- Price changes can happen within milliseconds or even microseconds, with hundreds of updates taking place every second.
- Users need to send orders to the server and make decisions based on real-time price changes.
Imagine thousands of users simultaneously reading price changes and sending orders to the server. With REST, the only way to receive data is to poll the server as frequently as possible. As HTTP requests include headers, other properties, and sometimes bodies, frequent polling can overwhelm server bandwidth. Thousands of users accessing a high-demand resource at once creates bottlenecks – a problem that real-time APIs are designed to prevent.
A WebSocket API enables full-duplex communication, maintaining an open connection between the client and server so messages can flow in both directions instantly. Here’s how WebSockets works:
- The client sends a WebSocket handshake request to the server.
- If accepted, the server upgrades the connection from HTTP to WebSocket.
- The client and server can send messages over the persistent connection.
The advantages of WebSockets include:
- Full-duplex communication, so the client and server can send messages in both directions.
- Low latency, as messages are sent over a persistent connection.
- Support for different types of messages, such as text, binary, and even JSON.
- Support for authentication and authorization so the server can control who can access the connection.
This is what a typical WebSocket architecture looks like.
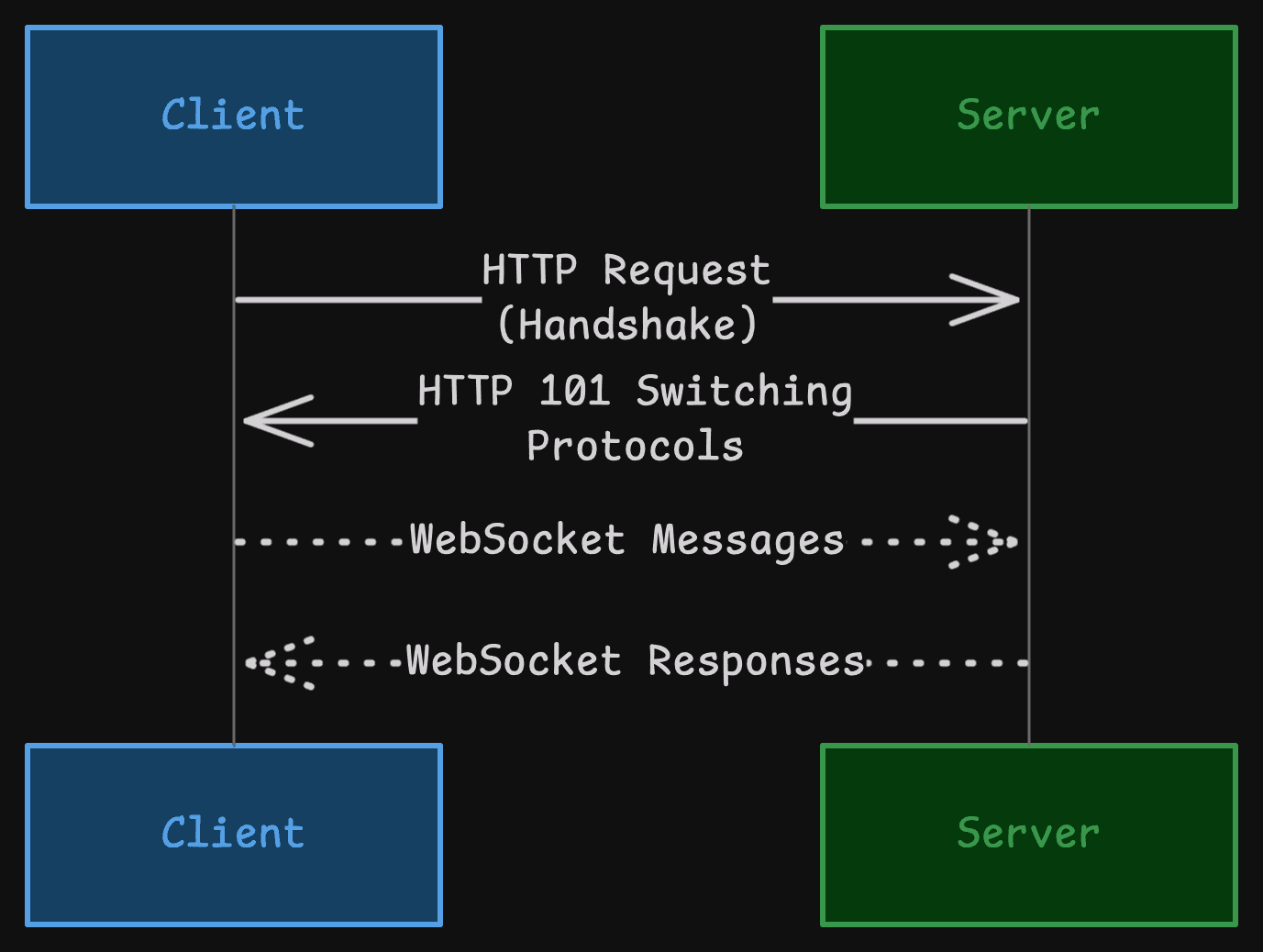
WebSockets is a great choice for our high-frequency trading application. Let’s see how this could be implemented in a Node.js application, using channels to allow users to send orders and receive price changes in real time.
import {WebSocketServer} from 'ws';
import Redis from 'ioredis';
const PORT = 8080;
// Redis configuration
const redisPublisher = new Redis(); // For publishing messages (e.g., orders)
const redisSubscriber = new Redis(); // For subscribing to price updates
// Create WebSocket server
const wss = new WebSocketServer({port: PORT});
console.log(`WebSocket server is running on ws://localhost:${PORT}`);
// Keep track of connected clients
const clients = new Set();
// Handle client connections
wss.on('connection', (ws) => {
console.log('New client connected');
clients.add(ws);
// Handle incoming messages from clients
ws.on('message', async (message) => {
try {
const parsedMessage = JSON.parse(message);
switch (parsedMessage.type) {
case 'PLACE_ORDER':
await handlePlaceOrder(parsedMessage.payload, ws);
break;
case 'SUBSCRIBE_PRICES':
handleSubscribePrices(ws);
break;
default:
ws.send(JSON.stringify({error: 'Unknown message type'}));
}
} catch (err) {
console.error('Error handling message:', err);
ws.send(JSON.stringify({error: 'Invalid message format or internal error'}));
}
});
// Handle client disconnections
ws.on('close', () => {
console.log('Client disconnected');
clients.delete(ws);
});
});
// Broadcast a message to all connected clients
const broadcast = (data) => {
clients.forEach((client) => {
if (client.readyState === client.OPEN) {
client.send(JSON.stringify(data));
}
});
};
// Handle "PLACE_ORDER" messages
const handlePlaceOrder = async (order, ws) => {
try {
const orderData = {...order, timestamp: new Date().toISOString()};
await redisPublisher.publish('orders', JSON.stringify(orderData)); // Publish the order to Redis
console.log('Order placed:', orderData);
// Respond to the client
ws.send(JSON.stringify({type: 'ORDER_PLACED', payload: {status: 'SUCCESS', orderId: Date.now()}}));
} catch (error) {
console.error('Error placing order:', error);
ws.send(JSON.stringify({error: 'Failed to place order'}));
}
};
// Handle "SUBSCRIBE_PRICES" messages
const handleSubscribePrices = (ws) => {
console.log('Client subscribed to price updates');
// Subscribe to the "prices" channel in Redis
redisSubscriber.subscribe('prices');
redisSubscriber.on('message', (channel, message) => {
if (channel === 'prices' && ws.readyState === ws.OPEN) {
ws.send(JSON.stringify({type: 'PRICE_UPDATE', payload: JSON.parse(message)}));
}
});
// Clean up when the client disconnects
ws.on('close', () => {
console.log('Client unsubscribed from price updates');
redisSubscriber.unsubscribe('prices');
});
};The code above creates a WebSocket server that listens on port 8080. When a client connects, the server handles the incoming messages and broadcasts them to all connected clients. Redis is used here to facilitate real-time publish-subscribe messaging by distributing price updates to WebSocket clients and handling client orders for asynchronous backend processing.
WebSocket APIs scale better vertically
WebSockets are generally better suited for vertical scaling (by increasing a server’s resources) than horizontal scaling. Here’s why:
- Persistent connections: WebSockets maintain bidirectional, long-lived connections between client and server, requiring each connection to stay open and active on the server. This makes it difficult to distribute workloads across multiple servers.
- Stateful management: Each WebSocket connection holds a state on the server, including user sessions and subscribed topics, which complicates horizontal scaling without a shared state.
Vertically scaling WebSocket APIs is a more suitable option, as a powerful server with sufficient CPU and memory can efficiently handle tens of thousands of WebSocket connections without inter-server communication overhead.
Server-sent events: A unidirectional alternative to WebSockets
If you don’t need users to send data to the server, you can opt to use server-sent events (SSE) instead of WebSockets. Unlike WebSockets’ full-duplex communication, SSE is unidirectional, sending events only from the server to the client. This is the technology behind RAMEN (Realtime Asynchronous MEssaging Network), Uber’s real-time push messaging platform . Uber uses RAMEN, built on SSE, to maintain persistent connections with millions of devices and deliver prioritized, real-time updates, such as trip statuses and driver locations. This platform allows Uber to handle over 1.5 million concurrent streaming connections and push 250,000 messages per second across multiple applications.
SOAP: A legacy standard for APIs
Some tools are so deeply ingrained in an industry that they defeat the forces of competition and time. Let’s discuss SOAP.
Introduced in 1999, SOAP (Simple Object Access Protocol) is one of the earliest protocols designed for web services. It established a standard for exchanging structured information in distributed systems, particularly in enterprise environments requiring robust security, transactionality, and reliability. While SOAP has mainly been replaced by REST, GraphQL, and gRPC in modern architectures, it continues to thrive in the banking, insurance, and healthcare industries.
SOAP operates over XML, making it verbose but highly structured, and it’s transport-agnostic, meaning it can run over protocols like HTTP, SMTP, or message queues. This flexibility and reliability have kept SOAP relevant when strict compliance, security, and transactional integrity are critical, which is why this architecture continues to power many of the world’s largest banks, insurance companies, and healthcare providers.
SOAP works by defining an envelope for a message that includes:
- A header containing metadata for processing, such as authentication or transaction management.
- A body containing the actual data payload, typically encoded in XML.
Here’s an example of a SOAP request to fetch a product:
<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope" xmlns:prod="http://example.com/products">
<soap:Header/>
<soap:Body>
<prod:GetProduct>
<prod:ProductId>1</prod:ProductId>
</prod:GetProduct>
</soap:Body>
</soap:Envelope>And here is the response:
<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope">
<soap:Header/>
<soap:Body>
<GetProductResponse>
<Product>
<Id>1</Id>
<Name>Product 1</Name>
<Price>10.99</Price>
<Description>This is a product description</Description>
</Product>
</GetProductResponse>
</soap:Body>
</soap:Envelope>Although SOAP requests may seem verbose compared to REST or gRPC, the protocol compensates with its focus on reliability and security. SOAP natively supports WS-Security, which includes encryption, digital signatures, and token-based authentication. Other benefits of SOAP include:
- SOAP supports ACID transactions through WS-AtomicTransaction , ensuring operations like money transfers are executed reliably without partial failures.
- Unlike REST and GraphQL, which rely on HTTP, SOAP can operate over multiple transport protocols, including SMTP and JMS, enabling broader integration options.
- SOAP includes WS-ReliableMessaging, which guarantees message delivery even in unreliable networks. This is critical for scenarios like inter-bank communications or cross-border payments.
Scaling with SOAP
Scaling SOAP-based systems presents unique challenges due to their stateful nature, verbose XML payloads, and reliance on complex features like transactional messaging and WS-Security.
Choosing SOAP with the expectation of high performance may be unrealistic. However, scaling is not necessarily about how fast a system can process but also about how solid the system can be. For example, SOAP handles long-running operations efficiently with asynchronous messaging over protocols like SMTP and XMPP, ensuring reliability and retries without overloading the system.
While REST, GraphQL, and gRPC have largely replaced SOAP, it is a legacy technology valued for its reliability, security, and interoperability. However, SOAP’s performance and scalability limitations make it less suitable for modern architectures.
Making pragmatic choices
Choosing the right API architecture for your needs doesn’t have to be complicated.
REST remains the safest choice for most applications due to its simplicity, predictability, and extensive industry adoption. Scalability challenges are well-documented, with countless resources offering proven solutions. The mature REST ecosystem provides powerful tools like Swagger, OpenAPI, and Speakeasy, a tool that automatically generates SDKs from an OpenAPI specification.
If real-time interactions are a priority, WebSockets and SSE offer efficient solutions to complement REST. Other standards are valuable but often better suited to specific use cases.
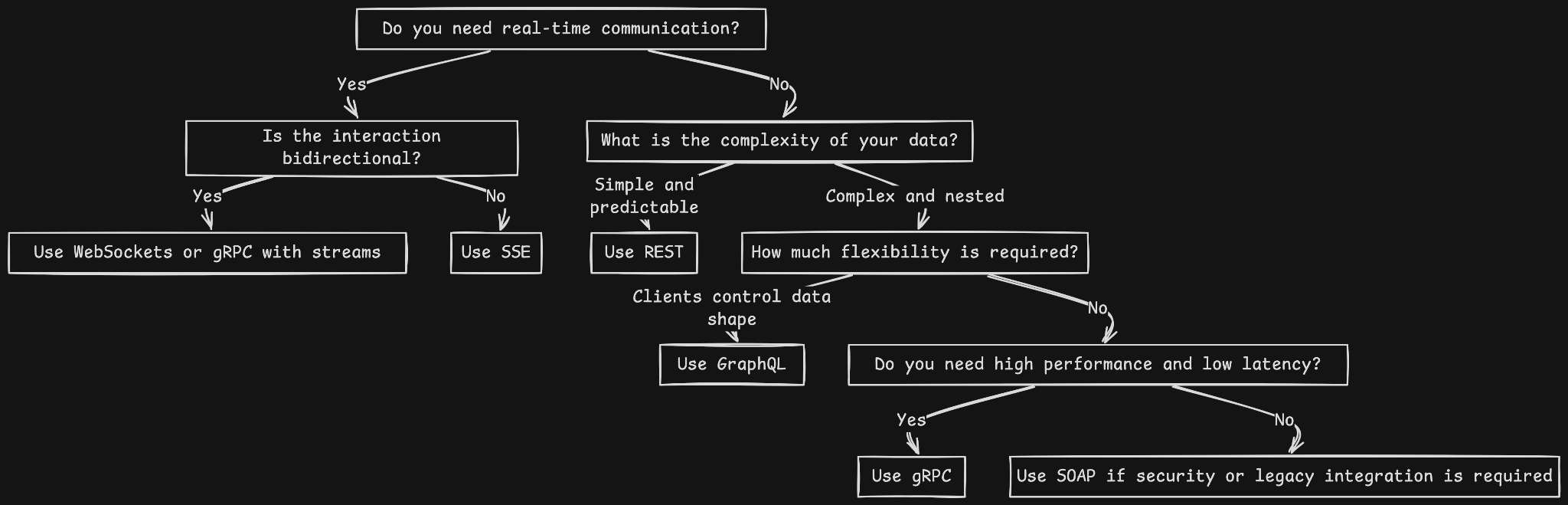
To simplify the decision-making process, we’ve created a flowchart-style framework to help you identify the most suitable architecture based on your project’s requirements. This is complemented by a decision table that maps everyday use cases to recommended architectures with concise justifications.
Decision flowchart
Decision table
| Scenario | Recommended architecture | Why? |
|---|---|---|
| Building a basic CRUD API | REST | Simple, widely supported, and intuitive for basic client-server communication. |
| Large-scale, real-time collaboration | WebSockets | Supports bidirectional, low-latency communication, ideal for applications like Slack. |
| Real-time updates, unidirectional | SSE | Lightweight and easy for server-to-client real-time updates. |
| Highly flexible data retrieval | GraphQL | Allows clients to fetch only the needed data, reducing over- and under-fetching. |
| Performance-critical microservices | gRPC | Binary serialization with Protobuf ensures low latency and high throughput. |
| Enterprise-grade financial system | SOAP | Provides transactional integrity, built-in security, and reliable messaging. |
| Multi-client application with evolving needs | GraphQL | Adaptable to various client needs without requiring API versioning. |
How to use the framework
- Follow the flowchart to narrow your options based on project requirements.
- Use the decision table to confirm the best fit for your specific scenario.
By understanding the trade-offs and aligning your choice with your application’s goals, you can make an informed, pragmatic decision.
Last updated on