SDKs
Lean SDKs with Standalone Functions
Georges Haidar
August 16, 2024 - 6 min read
Today we’re introducing a feature for every Speakeasy-generated TypeScript SDK, called Standalone Functions. This feature makes it possible for your users to build leaner apps on top of your API, that can run in the browser, or any other environment where performance is an important consideration.
The short version
Rather than needing to import the entire library, your SDK users will be able to select specific functions they want to use. Here’s what the change looks like with Dub’s SDK :
import { Dub } from "dub";
async function run() {
const dub = new Dub();
const count = await dub.links.count();
console.log("Link count:", count);
}
run();Into this:
import { DubCore } from "dub/core.js";
import { linksCount } from "dub/funcs/linksCount.js";
async function run() {
const dub = new DubCore();
const result = await linksCount(dub);
if (!result.ok) {
throw result.error;
}
// Use the result
console.log("Link count:", result.value);
}
run();All the SDK’s unused functionality: methods, Zod schemas, encoding/decoding helpers and so on, will be excluded from the user’s final application build. The bundler will tree-shake the package and handle minification of the unused code from within the modules.
Additionally, standalone functions return a Result<Value, KnownErrors> type
which brings about better error handling ergonomics.
Note
Standalone functions do not replace the existing class-based interface. All Speakeasy TypeScript SDKs now provide both functions and classes. We think they are both equally valid ways for developers to work with SDKs. The decision on which style to use can be based on the project you’re building and what constraints are in place.
Impact
Combining standalone functions with ES Modules yields massive savings as shown in the bundle analysis for the sample programs above.
Using dub@0.35.0 with the class-based API:

Using dub@0.36.0 with the standalone functions API:
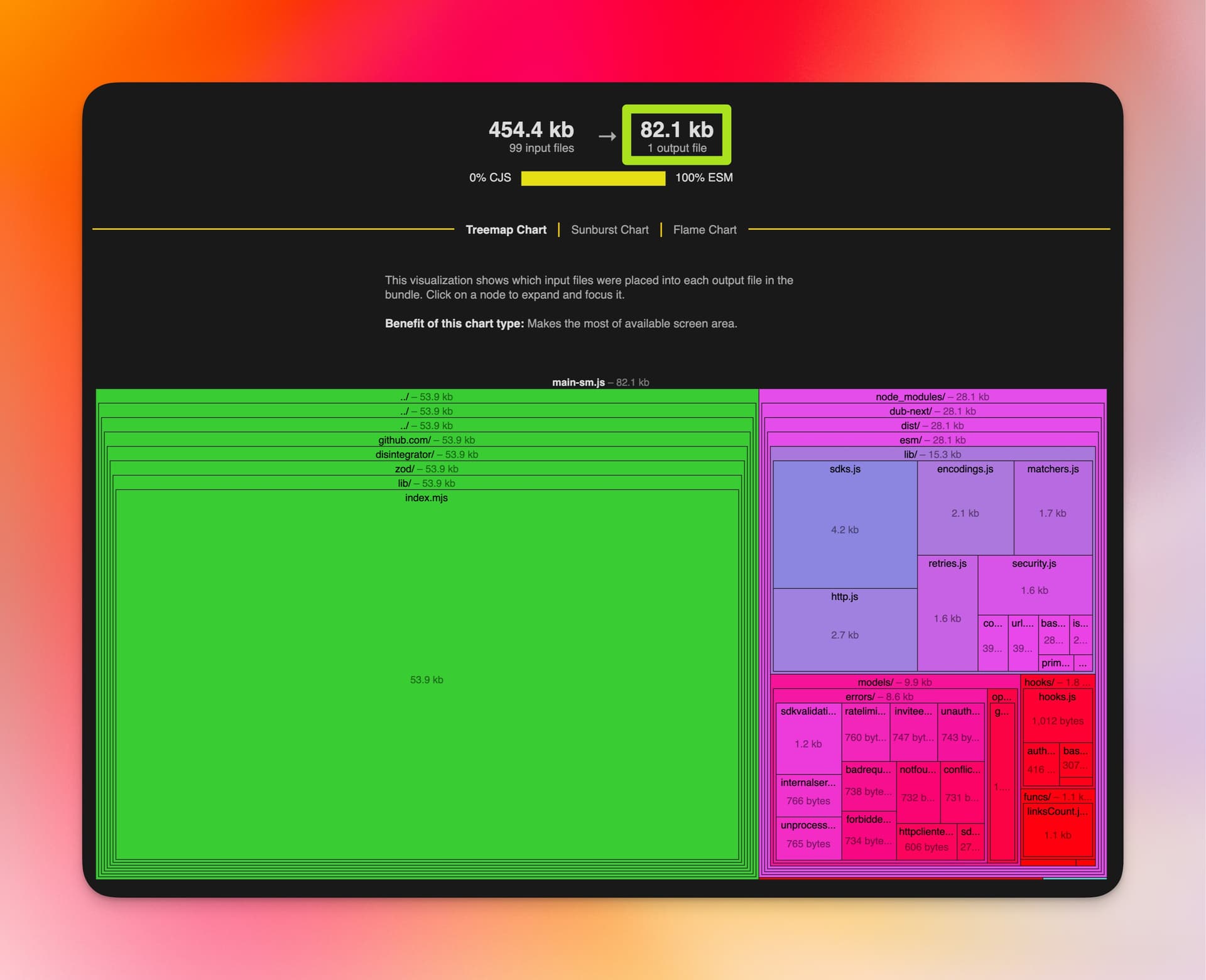
Please note that the sizes above are before compressing the bundles with Gzip or Brotli. The uncompressed size is a good proxy for metrics like JavaScript parsing time in the browser. Regardless, it’s a great idea to compress code before serving it to browsers or using a CDN that handles this for you.
Note
Our TypeScript SDKs use Zod to build great support for complex validation and (de)serialization logic. If you are already using Zod in your application then consider excluding its size (~50KB) when thinking about the numbers above. The impact is even more compelling in this case.
The long version
Many SDKs are built around the concept of a class that you instantiate and, through it, access various operations:
import { Beezy } from "@speakeasy-sdks/beezyai";
const beezy = new Beezy(); // The SDK class
const stream = await beezy.chat.stream({
prompt: "What is the most consumed type of cheese?",
model: "ex-30b",
});
// Use the result...This works great from a developer experience perspective especially if you are using an IDE with language server support. You can autocomplete your way to most functionality and breeze through your work.
If we dig under the surface, we would likely find a typical SDK is arranged like so:
However, if you’re building a web app/site, there is a downside to this approach
that is not immediately apparent: the entire SDK will be included in your app’s
bundle because there is little or no opportunity to tree-shake or exclude unused
code from the SDK. If we were to bundle the snippet of code above, then all the
code in the Beezy, Chat, Files and ChatHistory classes as well as all of
the code that supports those classes an their methods, such as pagination and
multipart request helpers, will be include in our app. Yet, we only called
beezy.chat.stream().
A brief crash course on bundlers and tree-shaking
A lot of web apps are built using front-end frameworks with bundlers such as Rollup , Webpack , ESBuild , Turbopack . Bundlers are responsible for a bunch of tasks including taking your TypeScript code and code from all the libraries you used, converting into a JavaScript files that can be loaded on the browsers. They also employ techniques to reduce the amount of JavaScript to load such as minifying the code, splitting a bundle into smaller parts to load functionality incrementally and tree-shaking to eliminate unused code from your codebase and the libraries you’ve used.
Tree-shaking is the process of identifying what parts of a JavaScript module were used and only including that subsection of the module. Here’s an example from ESBuild:
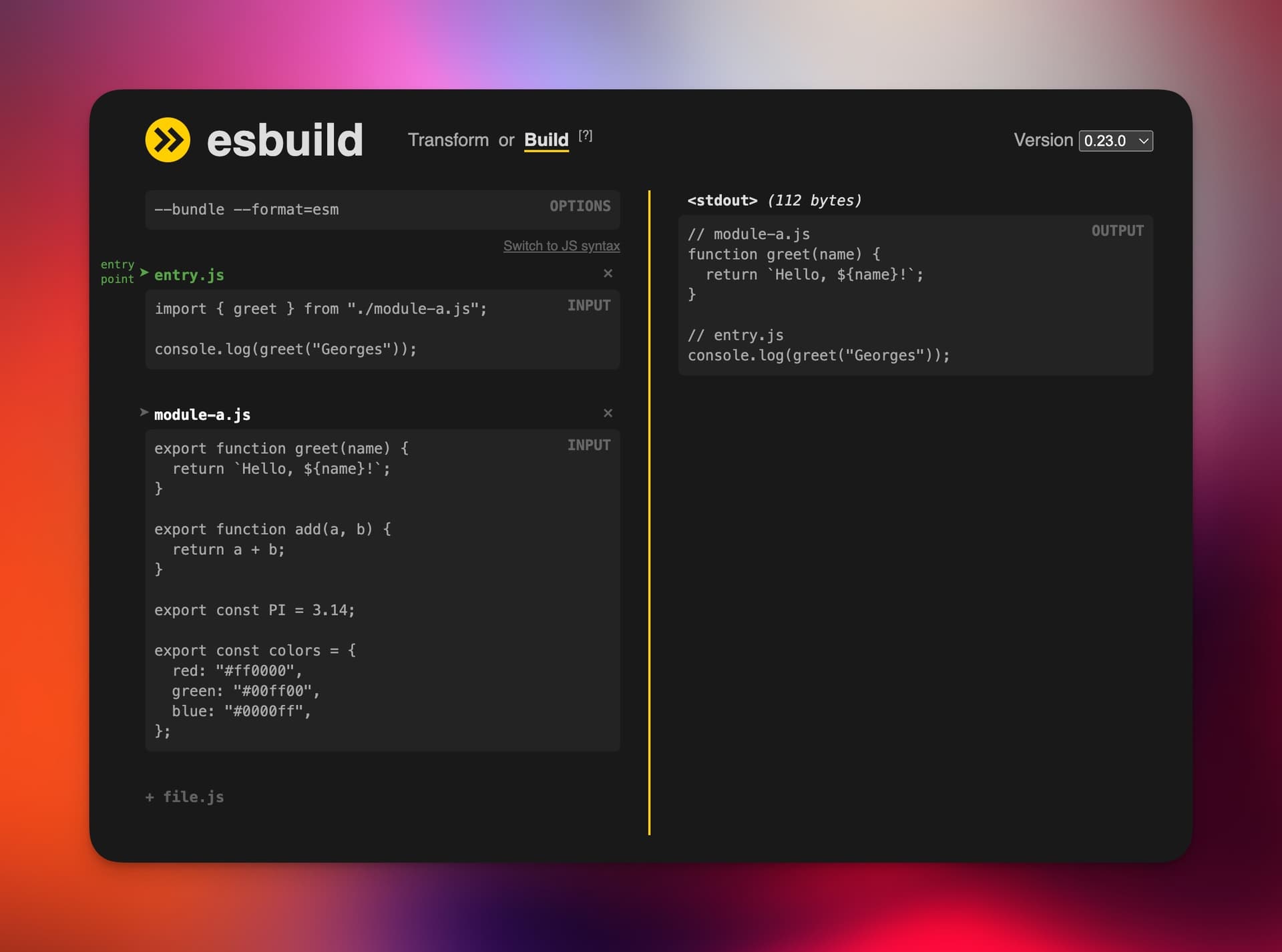
(Playgound link for the screenshot above )
Notice how in the build output, the add, PI and colors exports were not
included. Most bundlers are capable of tree-shaking, some apply better or more
heuristics than others, but generally the rule is to analyze which module
exports were used and leave out the rest.
And we’re back
So if we understand how tree-shaking works, we can arrange our SDK code a little
differently and greatly reduce the impact of our package on a web app’s total
bundle size. This is what’s new in our recent changes to the generator. We now
create a folder in every TypeScript SDK at src/funcs/ and emit standalone
functions. Here’s a simplified example of one:
import { BeezyCore } from "../core.js";
export async function chatStream(
client: BeezyCore,
req: ChatRequest,
): Promise<
Result<
EventStream<ChatCompletion>,
ForbiddenError | RateLimitError | TimeoutError
>
> { /* ... */ } The interesting change is that instead of attaching methods to classes, we designed functions to take a tiny “client” as their first argument. This small inversion means bundlers can dial it up to the max with their tree-shaking algorithms since functions are module-level exports.
Playing the long game
When you peer into a function’s source code today, you’ll notice it’s more verbose than a one line call to a massive HTTP client abstraction. There’s code to validate data with Zod schemas, encode query, path and header parameters and execute response matching logic. This was a deliberate decision because it allows us, and by extension you, to have fine-grained control over tree-shaking. Whereas deep abstractions are very appealing at first, they end up unnecessarily dragging in all the functionality an SDK provides even if small subsets of it are needed. We’re choosing shallower abstractions instead and reaping the benefits.
From the results we’ve seen so far, we think standalone functions are the right building block for modern web apps. We’re excited to see what you’ll build with them.